
国产AI芯片两个倡导: 模子遮蔽+集群边界才略 | 百度智能云王雁鹏
当国产AI芯片接连发布、估值高潮之际,一个机敏的问题依然悬在头顶:它们果然能撑起下一代万卡集群与万亿参数模子的锻真金不怕火吗?
一边是市集对替代决策的进军期待,另一边是英伟达在利润与估值上仍大喊大进……
百度智能云AI计较首席科学家王雁鹏在量子位MEET2026智能畴昔大会上,基于百度昆仑芯在大边界坐褥环境中的实战教化指出:
评判芯片实力的范例已从单纯的算力数值,转向了能否表露撑抓从百亿到万亿参数、从远大模子到MoE架构、从单模态到多模态的齐备模子谱系锻真金不怕火,并能在万卡乃至更大边界集群上已矣高效延迟。
在演讲中,王雁鹏系统拆解了大边界锻真金不怕火中集群表露性、线性延迟与模子生态三大中枢挑战的攻坚旅途,并报恩了行业对MoE时期硬件旅途的宥恕。
他以为,即即是参数激增的MoE模子,“小芯片搭大集群”的旅途依然可行,其关键在于极致的通讯优化与系统级协同筹画。

为齐备呈现王雁鹏的念念考,在不改造愉快的基础上,量子位对演讲本质进行了整理裁剪,但愿能给你带来更多启发。
MEET2026智能畴昔大会是由量子位主理的行业峰会,近30位产业代表与会接头。线下参会不雅众近1500东说念主,线上直播不雅众350万+,获取了主流媒体的庸碌关注与报说念。
以下为王雁鹏演讲全文:
民众好,我是来自百度智能云的王雁鹏,我很长一段期间皆在逍遥AI基础智力确立的使命。今天想跟民众共享的本质是,咱们如安在坐褥环境中边界化利用咱们的国产芯片
最近国产芯片热度很高,许多产物不息上市,也获取了很高估值。似乎国产芯片立时就要在大边界坐褥环境落地。但同期,英伟达仍然保抓极高的利润率和高涨的估值,市集仍然在购买其产物。
这两个看似矛盾的得意背后,其实反应了一个事实:要信得过把国产芯片用起来,难度依然格外大。不仅如斯,除了英伟达除外的外洋芯片供应商,也雷同莫得在大边界锻真金不怕火场景中信得过跑起来。
国产替代一定是渐进式经由。民众皆知说念在推理场景中问题不大,举例昆仑芯从第一代起就已在搜索线上系统已矣全量推理,信得过辛苦在大边界锻真金不怕火场景内部。
大边界锻真金不怕火每每是上万卡的同步系统,任何一台卡中断皆可能导致任务重启。
比如,在100张卡的时候灵验锻真金不怕火期间是99%,但当1%期间因为中断挥霍的话,线性延迟到一万张卡则意味着总共这个词集群不可用了。因此,第一个要贬责的即是集群表露性问题。
在芯片层面,GPU天生是高故障率器件:晶体管数目多、算力高、功耗大,同期专注于计较导致监控才略弱,合座比CPU的故障率进步多个量级。
在这方面咱们有两类教化:
1、事先细巧化监控与考证:
咱们必须假定芯片可能存在多样问题——初始变慢、精度很是、数据不一致等,因此需要系统级技能提前定位可能的故障,而不可依赖芯片自己的报错才略。尤其是在静默伪善场景中,系统需要偶然精确定位故障节点,不然锻真金不怕火会永恒无法复现。
2、故障后的快速还原才略:
不论故障率何如,总要幸免大边界重算,因此咱们构建了透明Checkpoint和快速还原机制,尽量减少亏蚀。
一个万卡集群必须已矣线性延迟,不然唯一千卡、两千卡的边界兴味不大。
咱们大约阅历了三个阶段:
百卡集群上,考证期间可行性,关键在于RDMA通讯期间的适配与优化。
千卡集群上,由于集中不再平等,比如咱们不可把任何两个芯片或者两台机器作为在集中任何方位部署性能皆一样,因此也需要作念好集中亲和性颐养等复杂优化。
万卡集群则是更大的挑战,面临多任务、多并行战略(PP、TP、EP等)带来的流量竞争,必须已矣芯片与集中的相接筹画。
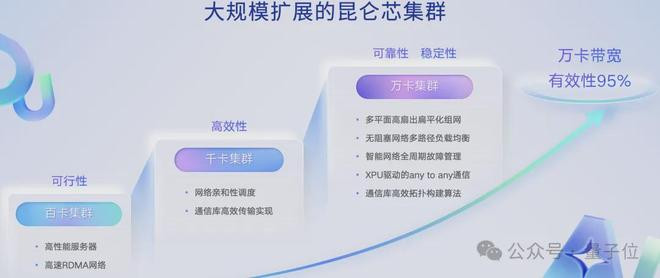
咱们的中枢逻辑叫:XPU驱动的anytoany的通讯
以XPU为中枢,在通讯经由中绕过CPU多样影响,径直用XPU驱动咱们的集中。针对不同流量有不同优先级作念总共这个词任务的最优,经过这少许咱们不错把大边界延迟作念上去。
英伟达最强的护城河并不仅仅硬件,而是昔时十多年千里淀的模子生态:千千万万种模子变体、算子体系、框架适配,这些皆让英伟达在锻真金不怕火精度上保抓总共辖路性。
在大模子时期,由于Transformer这套架构相对长入,国产芯片迎来了契机。
但可能许多东说念主忽略的少许是:
面前Scale换了一个维度,造成了模子参数的Scale和任务边界的Scale。而这意味着模子参数不错有不同的边界,举例十亿、百亿、千亿,同期咱们不错跑到不同硬件平台上,比如百卡、千卡、万卡,这两个维度的Scale则会带来总共这个词系统的Scale。
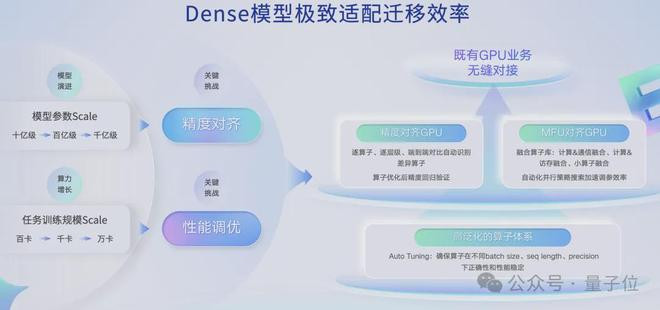
不同于原本模子架构的Scale,算子映射到硬件上头会有不同的size,不同阵势,不同并行的战略,这个情况下算子能不可表露地跑出来。咱们看到它会在精度和性能上皆会存在挑战,尤其是精度方面的挑战。换了一个平台,以致可能因为“算子写得诀别”、“精度差少许”皆可能导致两个月的锻真金不怕火白跑。
因此咱们作念了高度泛化的算子体系,针对不同的算子的size作念了高强度的泛化,同期在泛化基础上还作念到小边界考证精度,幸免每次皆使用万卡对比,从而保证大边界锻真金不怕火的可靠性。
面前要紧的发展标的是MoE,它能在不进步激活边界的情况下延迟模子参数,延续ScalingLaw。
但MoE基础上对系统架构也带来新的挑战,模子参数变大了,输入序列变长,意味着通讯占比进步了,对总共这个词模子架构皆会有改造
因此需要极致的通讯优化,以及显存的协同,与计较overlap,来完成MoE系统的适配。
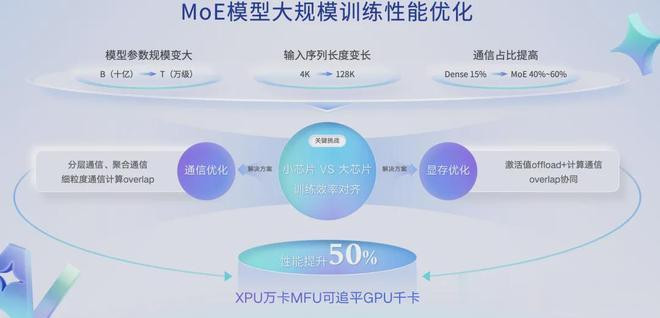
咱们的论断是,即即是MoE模子,小芯片搭大集群的花样依然可行
多模态模子则带来另一类问题,不同的模态会带来不同的锻真金不怕火强度,不同模态的计较,还用原本的同构拆分措施的话会导致锻真金不怕火的遵循格外低,典型情况下MFU可能皆不到10%。
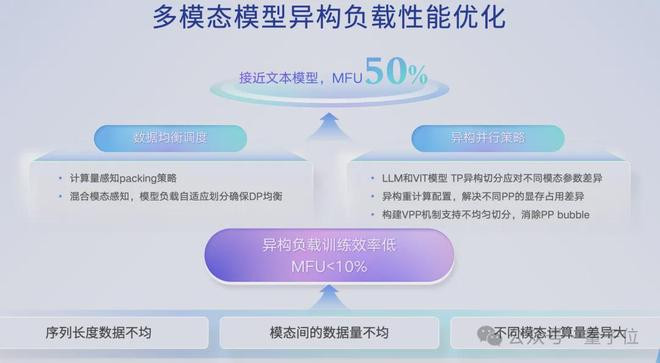
针对这个需要作念异构数据平衡的颐养,适配异构并行战略,使得系统偶然凭据咱们workload动态地作念并行战略。不管模子是什么样的,皆能找到最优的初始战略适配模子,在这一块需要作念优化。
揣摸国产芯片“能否信得过用起来”的范例,咱们以为有两个关键维度:
面前咱们在模子遮蔽上基本达到主流大模子体系,在边界上已能跑万卡任务,畴昔还会向数万卡鼓励。

最近民众关注TPU,就是因为Google偶然用格外优秀的Gemini证实TPU的锻真金不怕火才略——模子绑定硬件,硬件才能信得过被摄取。
雷同,昆仑芯也需要绑定优秀的自研模子。
面前咱们在百度QianfanVL、百度蒸汽机皆取得较最先的模子后果,并依然已矣全栈基于昆仑芯的锻真金不怕火。畴昔咱们会不息勤恳,让更先进的模子在咱们昆仑芯上头全栈锻真金不怕火出来。